아래는 GPT-4에 대한 공식 소개 입니다.
우리는 OpenAI의 딥 러닝 확장 노력의 최신 이정표인 GPT-4를 만들었습니다. GPT-4는 많은 실제 시나리오에서 인간보다 능력이 떨어지지만 다양한 전문 및 학술 벤치마크에서 인간 수준의 성능을 보여주는 대규모 다중 모드 모델(이미지 및 텍스트 입력을 수락하고 텍스트 출력을 내보냄)입니다.
예를 들어, 시험 응시자의 상위 10% 정도의 점수로 모의 변호사 시험을 통과합니다. 반면에 GPT-3.5의 점수는 하위 10% 정도였습니다. 우리는 6개월 동안 적대적 테스트 프로그램과 ChatGPT의 교훈을 사용하여 GPT-4를 반복적으로 조정하여 사실성, 조종성 및 가드레일을 벗어나지 않는 측면에서 (완벽하지는 않지만) 최고의 결과를 얻었습니다.
지난 2년 동안 우리는 전체 딥 러닝 스택을 재구축했으며 Azure와 함께 작업 부하를 위해 처음부터 슈퍼컴퓨터를 공동 설계했습니다. 1년 전 우리는 시스템의 첫 번째 "테스트 실행"으로 GPT-3.5를 교육했습니다. 몇 가지 버그를 찾아 수정하고 이론적 기반을 개선했습니다. 그 결과 GPT-4 훈련 실행은 (적어도 우리에게는!) 전례 없이 안정적이었으며 훈련 성능을 미리 정확하게 예측할 수 있는 최초의 대형 모델이 되었습니다. 우리는 신뢰할 수 있는 확장에 계속 초점을 맞추면서 미래의 기능을 점점 더 미리 예측하고 준비하는 데 도움이 되는 방법론을 연마하는 것을 목표로 합니다.
| Simulated exams | GPT-4estimated percentile | GPT-4 (no vision)estimated percentile | GPT-3.5estimated percentile |
| Uniform Bar Exam (MBE+MEE+MPT)1 | 298 / 400~90th | 298 / 400~90th | 213 / 400~10th |
| LSAT | 163~88th | 161~83rd | 149~40th |
| SAT Evidence-Based Reading & Writing | 710 / 800~93rd | 710 / 800~93rd | 670 / 800~87th |
| SAT Math | 700 / 800~89th | 690 / 800~89th | 590 / 800~70th |
| Graduate Record Examination (GRE) Quantitative | 163 / 170~80th | 157 / 170~62nd | 147 / 170~25th |
| Graduate Record Examination (GRE) Verbal | 169 / 170~99th | 165 / 170~96th | 154 / 170~63rd |
| Graduate Record Examination (GRE) Writing | 4 / 6~54th | 4 / 6~54th | 4 / 6~54th |
| USABO Semifinal Exam 2020 | 87 / 15099th–100th | 87 / 15099th–100th | 43 / 15031st–33rd |
| USNCO Local Section Exam 2022 | 36 / 60 | 38 / 60 | 24 / 60 |
| Medical Knowledge Self-Assessment Program | 75% | 75% | 53% |
| Codeforces Rating | 392below 5th | 392below 5th | 260below 5th |
| AP Art History | 586th–100th | 586th–100th | 586th–100th |
| AP Biology | 585th–100th | 585th–100th | 462nd–85th |
| AP Calculus BC | 443rd–59th | 443rd–59th | 10th–7th |
ChatGPT 및 API(대기자 명단 포함)를 통해 GPT-4의 텍스트 입력 기능을 출시합니다. 보다 폭넓은 가용성을 위해 이미지 입력 기능을 준비하기 위해 단일 파트너와 긴밀히 협력하여 시작하고 있습니다. 또한 AI 모델 성능의 자동 평가를 위한 프레임워크인 OpenAI Evals를 오픈 소싱하여 누구나 모델의 단점을 보고하여 추가 개선을 안내할 수 있도록 합니다.
기능
일상적인 대화에서 GPT-3.5와 GPT-4의 차이는 미묘할 수 있습니다. 작업의 복잡성이 충분한 임계값에 도달하면 차이가 나타납니다. GPT-4는 GPT-3.5보다 더 안정적이고 창의적이며 훨씬 더 미묘한 지침을 처리할 수 있습니다.
두 모델의 차이점을 이해하기 위해 원래 인간을 위해 설계된 시험 시뮬레이션을 포함하여 다양한 벤치마크에서 테스트했습니다. 공개적으로 사용 가능한 최신 테스트(올림피아드 및 AP 무료 응답 질문의 경우)를 사용하거나 2022-2023 에디션의 연습 시험을 구매하여 진행했습니다. 우리는 이 시험을 위해 특별한 훈련을 하지 않았습니다. 시험에서 소수의 문제가 교육 중에 모델에 표시되었지만 결과가 대표적이라고 생각합니다. 자세한 내용은 기술 보고서를 참조하십시오.
| Benchmark |
GPT-4
Evaluated few-shot
|
GPT-3.5
Evaluated few-shot
|
LM SOTA
Best external LM evaluated few-shot
|
SOTA
Best external model (includes benchmark-specific training)
|
|
Multiple-choice questions in 57 subjects (professional & academic)
|
86.4%
5-shot
|
70.0%
5-shot
|
70.7%
|
75.2%
|
|
Commonsense reasoning around everyday events
|
95.3%
10-shot
|
85.5%
10-shot
|
84.2%
|
85.6%
|
|
Grade-school multiple choice science questions. Challenge-set.
|
96.3%
25-shot
|
85.2%
25-shot
|
84.2%
|
85.6%
|
|
Commonsense reasoning around pronoun resolution
|
87.5%
5-shot
|
81.6%
5-shot
|
84.2%
|
85.6%
|
|
Python coding tasks
|
67.0%
0-shot
|
48.1%
0-shot
|
26.2%
|
65.8%
|
|
DROP (f1 score)
Reading comprehension & arithmetic.
|
80.9
3-shot
|
64.1
3-shot
|
70.8
|
88.4
|
많은 기존 ML 벤치마크는 영어로 작성됩니다. 다른 언어의 기능에 대한 초기 감각을 얻기 위해 Azure Translate를 사용하여 57개 주제에 걸친 14,000개의 객관식 문제 모음인 MMLU 벤치마크를 다양한 언어로 번역했습니다(부록 참조). 테스트한 26개 언어 중 24개 언어에서 GPT-4는 라트비아어, 웨일스어, 스와힐리어와 같은 리소스가 적은 언어를 포함하여 GPT-3.5 및 기타 LLM(Chinchilla, PaLM)의 영어 성능을 능가합니다.
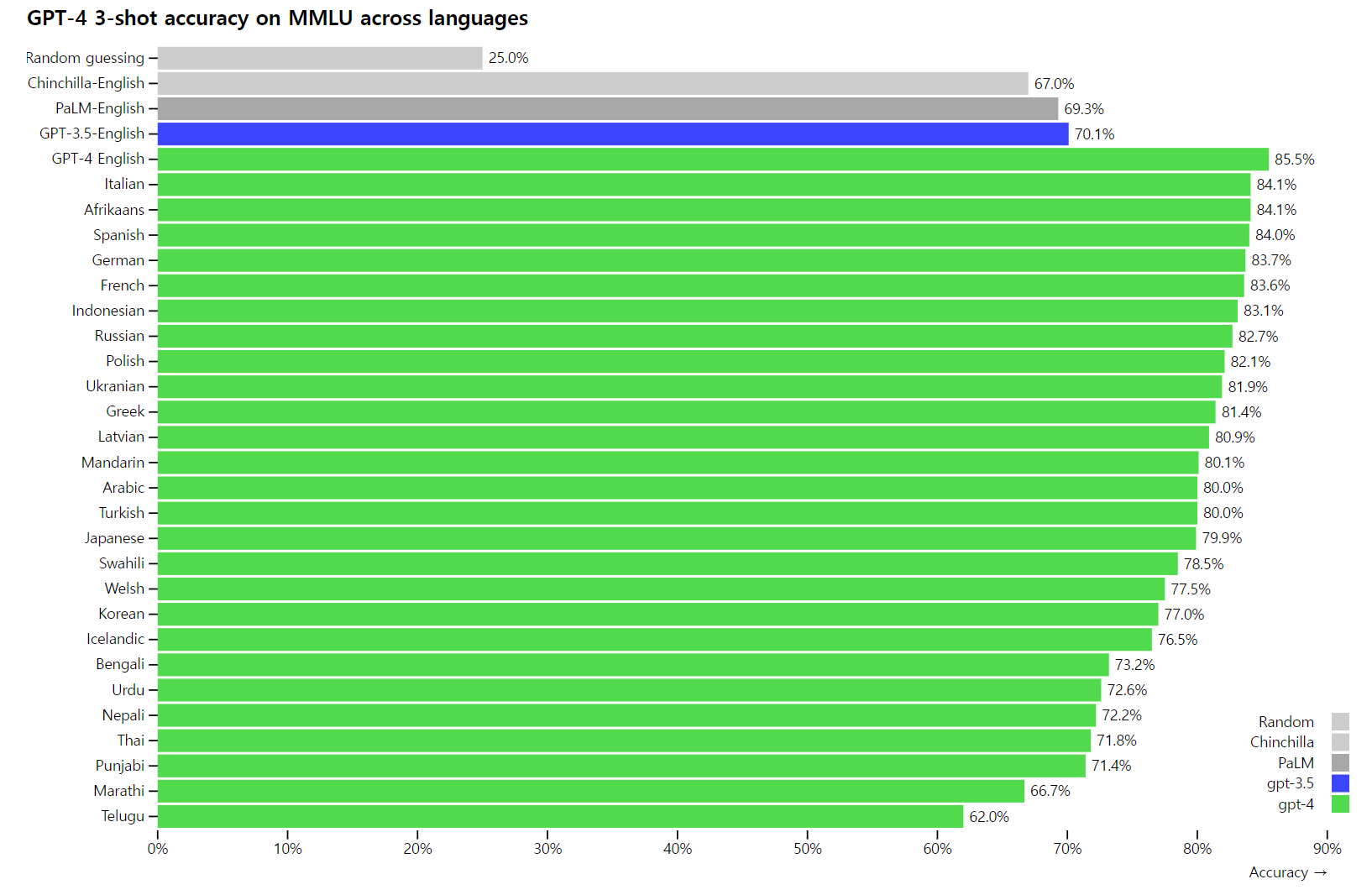
또한 내부적으로 GPT-4를 사용하여 지원, 판매, 콘텐츠 조정 및 프로그래밍과 같은 기능에 큰 영향을 미쳤습니다. 우리는 또한 정렬 전략의 두 번째 단계를 시작하면서 인간이 AI 출력을 평가하는 데 도움을 주기 위해 이를 사용하고 있습니다.
시각적 입력
GPT-4는 텍스트 및 이미지 프롬프트를 수락할 수 있으며 텍스트 전용 설정과 마찬가지로 사용자가 시각 또는 언어 작업을 지정할 수 있습니다. 구체적으로 산재된 텍스트와 이미지로 구성된 입력이 주어지면 텍스트 출력(자연어, 코드 등)을 생성합니다. 텍스트와 사진이 포함된 문서, 다이어그램 또는 스크린샷을 비롯한 다양한 영역에서 GPT-4는 텍스트 전용 입력에서와 유사한 기능을 보여줍니다. 또한 퓨샷 및 사고 사슬 프롬팅을 포함하여 텍스트 전용 언어 모델용으로 개발된 테스트 시간 기술로 보강할 수 있습니다. 이미지 입력은 여전히 연구 미리 보기이며 공개적으로 사용할 수 없습니다.
'IT소식' 카테고리의 다른 글
| Apple iPhone 15 Pro의 3nm A17 Bionic GeekBench 점수 유출, 인상적인 성능 업그레이드 공개 (0) | 2023.03.16 |
|---|---|
| "Claude" Anthropic의 ChatGPT 라이벌 (0) | 2023.03.16 |
| 유출: Xbox Series S 'Oreo' 테마 콘솔 및 컨트롤러를 획득하고 개봉했습니다. (0) | 2023.03.09 |
| Google One 모든 가입자에게 VPN 제공 예정 (0) | 2023.03.09 |
| 삼성전자에서 제작한 민트 초코 키보드 마우스 출시 (0) | 2023.03.09 |